Klasifikasi adalah suatu cara yang dilakukan untuk mengelompokkan obyek berdasarkan suatu karakteristik tertentu. Dalam bahasa pemorgraman Python, algoritma klasifikasi dapat dilakukan dengan beberapa cara. Salah satu algoritma klasifikasi adalah k Nearest Neighbors (kNN), di mana pengelompokan didasarkan kedekatan antar obyek. Model hasil mesin pembelajaran klasifikasi kNN dengan Python dapat digunakan untuk melakukan prediksi suatu obyek.
Bagaimana cara melakukan klasifikasi kNN dengan Python? Bagaimana cara melakukan predisi yang sesuai dengan algoritma klasifikasi kNN? Sobat idschool dapat mencari tahu jawabannya melalui ulasan di bawah.
Data Bunga Iris
Bagaimana proses klasifikasi kNN dengan Python pada halaman ini akan ditunjukkan melalui sebuah contoh. Data yang digunakan dalam contoh merupakan dataset bunga iris. Dataset bunga iris paling sering dijadikan sebagai contoh untuk latihan pengolahan data, termasuk klasifikasi kNN. Di mana dataset bunga iris dapat dapat diperoleh dengan cara mengunduh melalui UCI atau Kaggle.
Atau, dataset bunga iris juga terdapat dalam library scikit-learn yang dapat langsung dipanggil melalui Jupyter Notebook ketika komputer sudah terinstal Anaconda.
Sebelum ke bahasan bagaimana proses klasifikasi kNN dengan Python menggunakan dataset bunga iris, sebaiknya perlu mengetahui bagaimana isi atau bentuk dataset tersebut.
Data bunga iris adalah dataset berupa 150 ukuran-ukuran yang meliputi sepal length (panjang mahkota/daun bunga), sepal width (lebar mahkota/daun bunga), petal length (panjang kelopak), dan petal width (lebar kelopak). Semua ukuran dalam dataset bunga iris dinyatakan dalam sentimeter (cm). Klasifikasi kNN untuk dataset bunga iris akan mengelompokkan jenis bunga dalam tiga spesies yaitu iris setosa, iris versicolour, dan iris virginica.

Keterangan mengenai ketiga jenis spesies bunga iris tersebut terdapat dalam deskripsi data. Cara menampilkan deskripsi data dapat dilakukan melalui perintah print(iris_dataset[‘DESCR’]).

Untuk kumpulan data ukuran bunga terdapat pada iris_dataset[‘data’] dengan tipe data berbentuk arrayy. Ukuran-ukuran yang terdapat pada dataset bunga iris terdapat dalam lima 150 baris dan 4 kolom. Tampilan tipe data dan ukuran sebagian dataset bunga iris ditunjukkan seperti berikut.

Empat kolom berturut-turut merupakan ukuran untuk sepal length, sepal width, petal length, dan petal width. Sementara data 150 baris memuat ukuran bunga yang terbagi sama untuk spesies iris setosa, versicolor, dan virginica. Sehingga setiap spesies bunga iris terdiri dari 50 kumpulan data.
Baca Juga: Proses Pengerjaan Analisis Regresi Linear Sederhana Secara Manual (Tanpa Software)
Langkah-Langkah yang Dikerjakan Klasifikasi kNN dengan Python
Proses klasifikasi kNN dengan Python untuk dataset bunga iris di halaman ini menggunakan Jupyter Notebook dalam sistem Anaconda. Library yang digunakan untuk melakukan klasifikasi kNN untuk dataset bunga iris dalah scikit learn.
Langkah pengerjaan klasifikasi kNN dengan Python meliputi import data, membagi data menjadi data latih dan tes, proses klasifikasi kNN, dan melihat akurasi skor. Selain itu juga akan dilakukan prediksi data baru untuk melihat bagaimana hasil kerja klasifikasi kNN dengan Python.
1) Import Data
Langkah pertama adalah menyiapkan data yang akan diolah ke dalam Jupyter Notebook. Cara mengambil data dapat dilakukan melalui dua cara yaitu menggunakan pembacaan file dengan pandas atau import langsung dari library scikit-learn.
Pembacaan file dengan pandas berguna saat data yang akan digunakan tidak berada dalam library. Biasanya data yang dipanggil dengan pandas memiliki format csv dengan perintah pd.read_csv(iris_dataset). Perlu diperhatikan bahwa file data harus berada dalam satu folder dengan lembar pengerjaan Jupyter Notebook.
Untuk beberapa dataset contoh seperti iris dataset sudah terdapat dalam library scikit-learn sehingga dapat langsung diperoleh melalui proses import. Untuk memanggil dataset bunga iris dari library scikit learn dapat dilakukan dengan menuliskan perintah berikut.

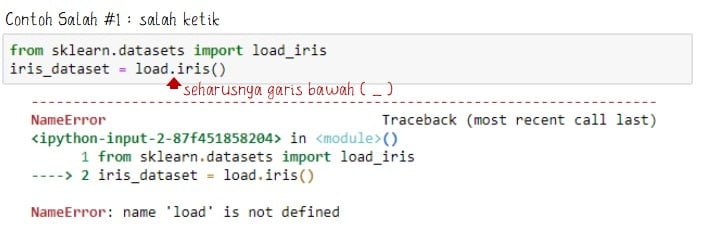
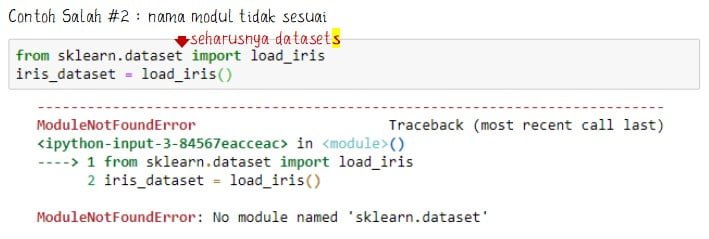
Jika proses import data berhasil makan tidak muncul tanda error. Jika proses import data tidak berhasil maka akan muncul error yang dapat disebabkan oleh beberapa kemungkinan.
Bentuk kesalahan biasanya ada penamaan yang tidak sesuai dengan library seperti ModuleNotFoundError: No module named ‘sklearn.dataset’. Atau keselahan juga terdapat salah ketik nama seperti NameError: name ‘load’ is not defined.
2) Membagi Data Menjadi Data Training dan Testing
Dataset bunga iris perlu dibagi dua menjadi data training dan data testing. Cara ini dilakukan untuk mengetahui seberapa akurat model yang nantinya dibuat dengan dataset tersebut.
Library scikit-learn memiliki perintah yang secara otomatis akan membagi data menjadi dua bagian. Bagian pertama adalah data training dengan jumlah sebanyak 3/4 bagian, sementara data testing sebanyak 1/4 bagian. Sehingga untuk banya data sama dengan 150 akan dibagi menjadi 112 untuk data training dan 38 untuk data testing.
Perintah untuk melakukan split data dengan library scikit-learn dilakukan dengan menuliskan dan mengeksekusi kode berikut pada Jupyter Notebook.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(iris_dataset[‘data’], iris_dataset[‘target’], random_state = 0)
Data training akan digunakan dan dipelajari dalam model mesin pembelajaran klasifikasi kNN. Sementara data testing tidak digunakan dalam pembelajaran dan akan berguna untuk melihat seberapa akurat model yang dihasilkan.
Baca Juga: Metode Penelitian Kualitatif
3) Proses Latih Data dengan Klasifikasi kNN
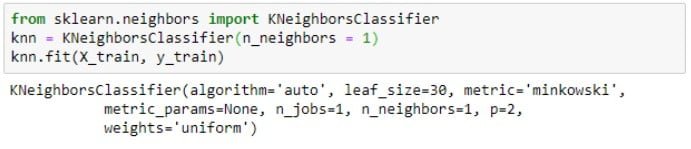
Proses klasifikasi kNN pada library scikit learn terdapat dalam sebuah kelas yang perlu dipanggil terlebuh dahulu. Perintah pemanggilan kelas dilakukan dengan menuliskan kode: from sklearn.neighbors import KNeighborsClassifier dalam Jupyter Notebook.
Setelah itu perlu juga untuk menentukan berapa banyak jumlah tetangga yang digunakan sebagai acuan klasifikasi. Kode perintah untuk menambahkan keterangan banyak tetangga sebagai acuan adalah KNeigborsClassifier(n_neighbors = x). Dengan x adalah bilangan yang menyatakan banyak tetangga yang menjadi acuan.
Data training akan dipelajari oleh machine learning klasifikasi kNN dengan Python melalui bagian perintah fit(X_train, y_train). Jika latih data berhasil diproses maka akan menampilkan output dengan keterangan seperti berikut.
4) Melihat Skor Akurasi Model Klasifikasi kNN
Seberapa besar keakuratan data latih pada dataset bunga iris dengan motode klasifikasi kNN dapat dicari tahu. Nilai skor keakuratan dapat diketahui menggunakan data test yang diperoleh pada waktu melakukan split data.
Sebelumnya data testing pada bagian split memiliki nama X_test dan y_test. Sehingga kode perintah untuk mengetahui besar akurasi model adalah knn.score(X_test, y_test).

Hasil akurasi model yang didapat adalah 0,936842… yang artinya akurasi model klasifikasi kNN adalah 97%. Hasil skor tersebut menunjukkan seberapa besar persentase keakuratan model untuk memprediksi data baru. Nilai skor 97% merupakan persentase yang besar untuk membuat kesimpulan bahwa prediksi yang dilakukan bernilai benar.
5) Contoh Cara Melakukan Prediksi
Sebagai contoh, diketahui ukuran sepal length, sepal width, petal length, dan petal width dari sebuah bunga iris berturut-turut adalah 5,4; 3,7; 1,5; dan 0,2. Empat ukuran tersebut perlu diimput dalam sebuah variabel dengan tipe data berupa array menggunakan numpy. Prediksi dilakukan dengan kode perintah knn.predict(nama_variabel) seperti yang dilakukan pada cara berikut.

Berdasarkan model klasifikasi kNN dengan Python yang telah dibuat dapat diketahui bahwa jenis spesies yang sesuai untuk bunga iris tersebut adalah iris setosa. Demikianlah tadi bagaimana proses yang dilakukan dalam klasifikasi kNN dengan Python. Terima kasih sudah mengunjungi idschool(dot)net, semoga bermanfaat!
Baca Juga: Pengertian dan Langkah Kerja pada Metode Penelitian Kuantitatif
permisi kak, untuk kolom id nya terbawa bagaimana ya kak?
Halo Zam, untuk menghilangkan sebuah kolom mungkin bisa gunakan pandas terlebuh dahulu.